Zhou Wei, Shi Jin, Wei Wen, Meng Qingmiao, Jiang Ming, Beijing Quanlu Communication Signal Research and Design Institute Co., Ltd.
Keywords: high reliability; high security; two by two taking two; three taking two; N taking M; intelligent degradation; security computer
1 Overview
In the traditional fault-safety system, the probability of the system outputting the dangerous side is equal to the product of the system failure probability and the probability of leading to the dangerous side after the failure, that is, D=(1-R)d. In order to reliably guide the safety side when a fault occurs, the fault-safety system needs to analyze all possible fault modes in the system in detail and design a corresponding fault detection circuit to handle various types of faults. At present, almost all security control systems are inseparable from high-performance processors. With the advancement of semiconductor technology, the computing speed, the number of cores, and the complexity of interface circuits of the processors are all increasing at a rapid rate. It has become increasingly difficult to overwrite and detect various failures of a single set of computing elements (such as memory failures, IO failures, bus failures, register failures, ALU unit failures, etc.). To achieve these complex detection functions at high speeds, the design complexity may even exceed the data path portion of designing a new processor. On the other hand, in the design of a fault-safety system, different strategies need to be adopted to achieve different degrees of synchronization between processors, such as clock synchronization or synchronization based on co-processing hardware circuits. With the increase of system bus and clock frequency, the design of a high-speed output stage hardware synchronizer has become increasingly difficult. These factors make it more and more expensive to implement a fault-safe system that uses hardware detection to cover all dangerous output failure modes. Some critics even believe that even after careful design, because the number of transistors in the current processor circuit is very large, in the case where the entire failed state space cannot be traversed, a failure mode cannot be covered by the failure detection circuit, so no matter Whether or not the fault detection circuit exists, the system is inevitably potential to output dangerous side data.
Another way to prevent the system from outputting the dangerous side is to increase the reliability of the system as much as possible. By reducing the probability of system failure, the probability of outputting dangerous side is reduced, thus ensuring system security. In the follow-up discussions, we can see that, under the existing technical conditions, the reliability of general-purpose computers has been greatly improved compared with the previous century, and the cost of using a general-purpose computer to build a highly reliable security system will be higher than the design cost. A fault-safe dedicated system costs less. This paper proposes a new type of fault-safe computing system that uses a general-purpose computing architecture. Because it greatly simplifies the design of fault detection circuits, the new system not only has a more concise system architecture, but also has a simpler and safer design than the traditional one. It also has the characteristics of high reliability, high security, low cost, easy design and maintenance, and sustainable development, and is more suitable for use in future highly integrated safety applications with stringent cost index requirements.
The structure of this paper is as follows. Chapter 2 introduces the classification of security systems. Chapter 3 introduces the basic principles of N-to-M systems. Chapter 4 introduces the key technologies of N-to-M systems. Chapter 5 details the various systems of N-to-M systems. The RAMS index is analyzed and compared with several typical fault-safety system performances. Chapter 6 introduces the application of N-retrieval M system in the train control system. Finally, the seventh chapter summarizes and forecasts the full text.
2 Security System Classification
2.1 Fault-safety system
According to the basic principle of the computing system, the data path of any computing system includes three parts in its design: 1) input acquisition; 2) logical operation; 3) output control. Since the three types of modules on the data path (input module, logic module, and output module) may fail, the conventional fault-safety system will design a corresponding fault detection module to detect the working status of the module on the data path in real time, once the fault is detected. The detection circuit immediately cuts off the data path, preventing erroneous outputs from being driven onto the output line.
A typical fault-safety system has several configurations such as 1OOlD, 1OO2D, 2OO2D, 2OO3D, and 2X2OO2D. Different configurations have different reliability and security. Assuming that the failure rate of a single system is P, and the probability of an output on the dangerous side after a failure is d, the reliability and security of the 1OO2D system, the 2OO3D system, and the 2X2OO2D system are shown in Table 1.

Through the analysis of the performance of each system, we can see that 2X2OO2D system and 2OO3D system are more reliable than single systems at the beginning, but from the time point of 3 times of single MTBF, both have sacrificed to some extent in the later period. Reliability, while the reliability of the three-in-two system is slightly higher than that of the two-by-two-two system, and the safety is the highest on the 2×2OO2D system.
2.2 High reliability system
Another type of safety system avoids the system from outputting the dangerous side by improving the reliability of the system. Such systems are widely used in the field of aerospace control. Because the requirements for system availability in such systems are more stringent than those in railway control systems, it is necessary to prevent the system from stopping the output by improving the reliability and availability of the system. Therefore, the requirements for fault tolerance of the system are more emphasized, such as in on-board systems. Commonly used three-way redundant security system. The security of such systems can be calculated according to equation (1):
S=1-D=1-(1-R)d=Rd (1)
From formula (1) it can be seen that the security of such systems is entirely proportional to the reliability of the system.
Similar to the fault-safety system, the onboard multi-channel redundancy system used in aviation has relatively high reliability and safety requirements for single systems. Therefore, the number of redundant paths is not much, and generally it takes three routes. What is used is often a highly reliable hard voter. With the advancement of software technology, distributed voting machines have gradually entered the process control system. In the following chapters, we can see that by increasing the number of redundant nodes in the system, combining a distributed voting mechanism, and adopting a smart degradation strategy, the N-to-M system will be able to further reduce the system requirements for single-component MTBF indicators. Improve the overall system performance.
3 N Take M System Principle
The N-input M system removes the complex fault detection part of the fault-safety system and instead considers that the single-computation node has the following features.
1) A single compute node failure is undetectable and can occur at any time;
2) After a single compute node fails, its output can be any possible value.
In order to ensure the reliability and safety performance of the system to a higher level than the traditional fault-safety system under the above conditions, the N-match system must be carefully designed in the following aspects.
3.1 Distributed voting
There is no function of fault detection, nor centralized voter (problem of single point failure). Therefore, the security of N-to-M system is completely established on the basis of distributed multi-way voting. Most of the nodes in the system are If consensus results can be obtained through distributed voting, then a majority opinion can be formed, and the system finally takes the result as output. The greater the number of nodes participating in distributed voting, the higher the reliability and security of the overall N-to-M system.
3.2 Byzantine Fault Tolerance
The premise that distributed multi-way voting can achieve security is to ensure that multiple independent computing paths get exactly the same input. Since the Byzantine failure hypothesis fault computing unit can send arbitrary messages to other computing units, and assuming these messages can be malicious, this feature severely undermines the preconditions of distributed multi-way voting. A Byzantine failure scenario in which a multi-node participates in voting is shown in Figure 1.
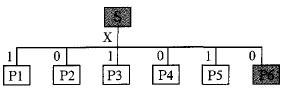
Figure 1 Influence of Byzantine Failure on Distributed Voting
Assume that the data sources S and P6 have a Byzantine failure, S sends uncertain messages {1, 0, 1, 0, 1} to each P1-P5, and P6 sends uncertain messages {1, 0, 1, 0) to P1-P5 nodes. 1) After the data exchange between nodes, the normal P1-P5 nodes will get the data shown in Table 2.
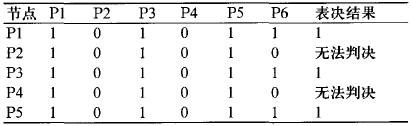
As can be seen from Table 2, in the distributed voting, although there are five normal nodes in the system, because the data received by each node is inconsistent and the result of the judgment is different, the final voting result cannot be consistent. The majority opinion has led to the failure of multi-node multi-way voting.
From the assumption of failure of Byzantium, we can see that traditional secure communication protocols cannot prevent Byzantine failure. In order to prevent Byzantine failure, Byzantine fault tolerance technology was developed in the 1980s. Leslie Lambert logically proves in his classical papers through rigorous mathematical derivation that it is assumed that the number of computational nodes in a system is N, the number of nodes that have suffered a Byzantine failure is M, and the conditions for message transfer using unsigned data Next, when N<3M+I, it is impossible to complete the majority vote in the remaining normal nodes and achieve agreement. Therefore, two different classic Byzantine fault tolerance algorithms are proposed.
One is based on normal communication between nodes, and assumes that the communication link is unreliable and unsigned OM algorithm, that is, by using M rounds of data communication between nodes, it can ensure that the normal NM nodes in the system can guarantee Obtain consistent input data and obtain correct results by multi-way voting.
Another fault-tolerant algorithm employs a signed message transmission mechanism in the node, and assumes that the data signed during system message transmission is an SM algorithm that cannot be forged by other failed nodes. The SM algorithm can guarantee the occurrence of Byzantine failure of M nodes when the minimum number of nodes is N=M+2.
To sum up, the Byzantine fault-tolerance protocol must be adopted in the N-M system to achieve distributed multi-way voting, and increasing the number of participating voting nodes will become the key to improving system availability and security.
3.3 Intelligent Degradation Process
In the N-input M system, through the system design, in the case of a small number of system failures, the remaining computing nodes can be utilized in an intelligently degraded manner instead of being stopped. For example, in a 10-for-8 system, if there is a 3-series fault, the remaining 7-series can no longer satisfy 10 to 8 operations. However, the distributed voting results system can decide and isolate three nodes that are inconsistent with the majority opinion, so the remaining 7-series intelligence can be degenerated into a 7-by-5 ​​system, and a highly reliable and highly secure system can still be maintained at this time. , so the system can still continue to work normally.
With an intelligent degenerate design, an N-eject M system can eventually tolerate only the remaining 2 series without failure, so the system can be regarded as having the same reliability as the N-equivalent two systems. Assuming that the system can tolerate the degeneracy from N to N-Me, the system reliability is:
![]()
From formula (2), it can be seen that due to the existence of the combination coefficient, the reliability of the system will increase rapidly when the number of system nodes N increases.
In the course of continuous failure and intelligent degradation of the N acquisition M system, the safety curve of the system is continuously declining. When N degenerates from M to Ne, only the N-series full Fail and at least the Me-system output dangerous side, the system will output the dangerous side, so the security of the degraded system is:
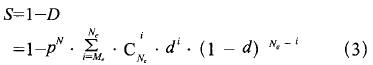
From formula (3) we can see that when system N increases, system security will increase exponentially.
In general, the cost function of a real system can be considered ![]() That is, as N increases, the system cost increases linearly, while increasing the MTBF value of the single system causes the system cost to increase by 1/λ. For an N-input M system, the reliability and security of the system are almost exponentially related to the number of nodes N. This means that as long as the number of nodes in the system is sufficient, it is always enough to offset the loss of MTBF performance on a single node, and It does not result in an exponential increase in cost, so that a general-purpose processor with a relatively low MTBF value can be used to build a highly reliable and highly secure system. After adopting the general-purpose computing node, because the general-purpose computing node is much cheaper than the special-purpose system, and at the same time simplifies the fault detection circuit, the value of N in the system can reach a higher level at an acceptable cost.
That is, as N increases, the system cost increases linearly, while increasing the MTBF value of the single system causes the system cost to increase by 1/λ. For an N-input M system, the reliability and security of the system are almost exponentially related to the number of nodes N. This means that as long as the number of nodes in the system is sufficient, it is always enough to offset the loss of MTBF performance on a single node, and It does not result in an exponential increase in cost, so that a general-purpose processor with a relatively low MTBF value can be used to build a highly reliable and highly secure system. After adopting the general-purpose computing node, because the general-purpose computing node is much cheaper than the special-purpose system, and at the same time simplifies the fault detection circuit, the value of N in the system can reach a higher level at an acceptable cost.
4 N take M system key technology
4.1 Byzantine Fault Tolerance Technology
Byzantine fault tolerance technology is the core of the system security layer. The efficient implementation of fault tolerant protocols is the basis for each independent computing unit to implement distributed computing and maintain consistency. Therefore, the implementation of this protocol is also the component with the highest requirements for software security. Comprehensive verification methods such as formal verification, big data test, equivalence check, and software and hardware co-simulation are needed to ensure software quality.
4.2 High-speed interconnection technology
Since Byzantine fault-tolerance protocol requires a large amount of inter-system communication overhead, if the speed of communication between systems cannot be guaranteed, the real-time nature of the system response will be greatly affected. This is one of the main reasons why the Byzantine fault-tolerance protocol has not been widely used. In the last ten years, the more efficient Byzantine fault-tolerance algorithm has achieved rapid development, and with the popularity of Gigabit Ethernet, high-speed Ethernet can be used as an internal high-speed interconnect bus for N-to-M systems, completely resolving the protocol level. The key issue. At the same time, in the future, to prevent possible lightning strikes on the IO side, optical Ethernet can be considered as a high-speed interconnect channel on the IO side.
4.3 Dynamic Migration Technology
After a computing node fails due to a failure, the system can detect the failed node through a coherence protocol and isolate it. At the same time, in order to ensure that the number of compute nodes available in the system does not gradually decrease with time, dynamic restart and online synchronization are required. Add new nodes to the system. The dynamic migration technology retains sufficient configuration data at the virtual machine level so that the previously-running virtual machine image can be restarted on other physical nodes through the management function of the platform within a very short time after the failure. After the new image is started, the status synchronization between the current computing node and the state machine synchronization protocol is achieved. After the synchronization is completed, the new image is used as a new computing node. Therefore, it has the ability to dynamically restore the number of nodes in a short period of time. . In the case where the total computing power of the system can be loaded, the compute nodes can not only be dynamically generated, but also have the ability to quickly synchronize to the online state through a coherence protocol. This feature eliminates the need for additional maintenance operations to keep the number of on-line processing nodes at a higher value for a long time, so that the MTTR time of the system can be reduced to a level very close to zero.
4.4 Safe Input and Output Technology
Traditional security input and output use different levels of security protocols to ensure that data can be transmitted end-to-end correctly. However, the traditional secure transmission protocol does not have the characteristics of Byzantine fault-tolerance. This is also the reason why the Byzantine fault-tolerance protocol must be adopted instead of the traditional security protocol in the N-M system. Fortunately, implementing Byzantine fault tolerance on input and output nodes does not require more processor resources than traditional security protocols. For example, a traditional output node may require a two-by-two, two-by-two structure to complete the security output, and the logical computing node and the output node are required to adopt a two-by-two-two structure. Therefore, a total of 4 processing nodes are required at the input and output ends.
In an N-input M system, it is assumed that the input/output stage has at least X processor nodes, and at the same time, at the logical computing stage, Y nodes cooperate with the input/input level to implement safe input and output functions. The Byzantine fault tolerance protocol requires X. +Y>M is +2 (M is the number of nodes that have failed due to Byzantium). When X=2 and Y=2, the system input/output stage can tolerate at most one node to have a Byzantine failure. Therefore, compared to the traditional two-by-two-two structure, the number of processors is reduced by half. Can achieve fault tolerance to Byzantine failure.
5 N Take M System Performance Analysis
5.1 System Reliability Analysis
Assuming N = 10, 20, and assuming that the single-line risk side output probability d = 0.05, using Matlab simulation to calculate M can be tolerated degradation to 4, 3, 2 cases, assuming that the degeneration process as Ne (Ne-2) System to use. The result is shown in Figure 2.
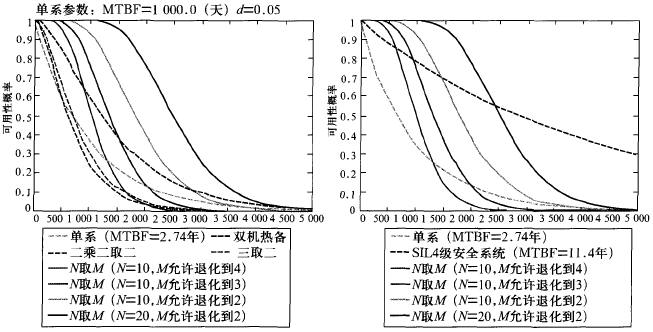
Figure 2 Comparison of reliability simulation results
As can be seen from Fig. 2, when N>10, the N-take-M system constructed with a single-line MTBF of 1000 days exceeds the reliability index of the SIL4 system at different time points. When N>10, in the time of single-line MTBF, the structure of N-to-M system has higher reliability than the traditional security system. When N>20, within 2 times of single-line MTBF time, N takes M. The systems all have higher reliability than traditional security systems.
5.2 System Security Analysis
In the process of system failure and intelligent degradation, the safety curve of the system continues to decline. When M is degraded from N to Ne, the system outputs the dangerous side only when N is full and at least has the Me series output dangerous side. The comparison between the security of the N access M system and the traditional security system and the European benchmark reference system simulation results is shown in FIG. 3 .
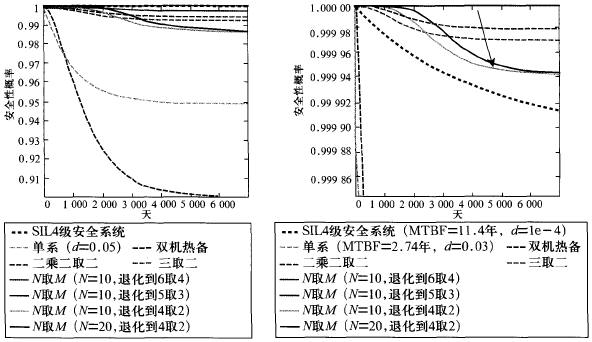
Figure 3 Comparison of security simulation results
The above simulation results show that the N-input M system (N ≥ 10) has reached the safety requirements of the European standard SIL4-level system, and exceeds the performance of the traditional fault-safety system.
5.3 System Cost Analysis
Figure 4 shows the simulation results of the corresponding (N, λ) curve clusters and the corresponding (c, N) curve clusters when the system performance degradation time tx takes different values:
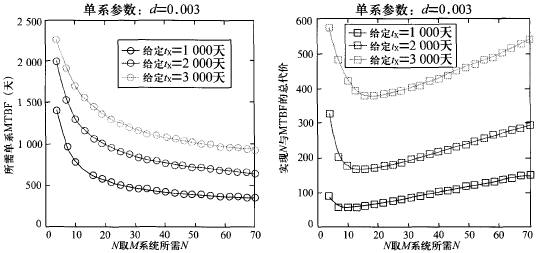
Figure 4 (N, MTBF) Curve Cluster and (c, N) Curve Cluster
From Figure 4, it can be seen that the marginal revenue will gradually decrease whether it is increasing N or increasing the MTBF of a single line. However, given any given safety performance index, adopting the N-based M-system solution will surely make the total cost of the system reach a minimum value, which cannot be achieved by traditional safety systems.
5.4 System Maintainability Analysis
After the hardware virtualization technology is adopted, the MTTR of the entire system can be reduced to a level close to 0 when the computing capacity is sufficient, because the system can rapidly realize the on-line and synchronization of the new system by redistributing resources. Therefore, from the perspective of system availability, the N-to-M system guarantees 100% availability almost at all times. In addition, by regularly maintaining the physical computing nodes in the system, the number of new nodes and old nodes in the system is maintained at an appropriate ratio, which can make the entire system to remain above the “five-for-three†structure for a longer period of time instead of degrading to four. The structure of 2. Therefore, the system will maintain a high level of security curve and availability level over a longer period of time.
5.5 System Capacity Analysis
A system adopting an N-to-M structure can easily increase the computational capability of the system by increasing the number of computational nodes N, without having to re-evaluate the security authentication and hardware design as the traditional security system. As previously discussed, adding new computing nodes under the premise of adopting hardware virtualization technology, the added cost is almost negligibly small, so overall, the computing capacity of the entire N-input M system will be quite large. Elasticity, from managing a station to covering all trains in an area, makes the N-to-M security architecture a promising choice for future control center control platforms.
6 train control system applications
Through the above analysis, the N-input M system guarantees high reliability and high security. At the same time, due to the adoption of a general-purpose processing node and a high-speed internal bus, it maintains a very high general-purpose data processing capability and versatility.
In terms of terrestrial applications, the use of virtualization technology, distributed execution, and other technologies can greatly increase the system's computing power. The original work that required several secure computer platforms to carry the information can be integrated. Traditional control mechanisms deployed on the line can also evolve into regional centralized control. For example, on the Wuhan-Guangzhou Passenger Dedicated Line, a total of 9 sets of RBC systems have been set up. Each set of RBC systems is a two-by-two-two-two structure, requiring a total of 36 dedicated hosts. In any RBC system, as long as one host in each dual system fails, it will cause CTCS-3 level control in the jurisdiction of the RBC system and reduce the operating efficiency. After adopting the security computing platform described in this article, not only will the overall cost drop, but also any two host failures will not be affected by the entire line of operations, ensuring the reliability of the system and the overall operating efficiency. On the other hand, the improvement of system computing capability also simplifies the business logic of the system. After adopting a centralized regional control center, not only RBC handover behavior can be greatly simplified, but also the cross-line operation of vehicles will be more convenient. The Security Computing Center is particularly suitable for deployment in cities where Beijing, Shanghai, Guangzhou and other cities converge. Similarly, other ground control systems, such as interlocking systems, train control center systems, temporary speed limit systems, track circuit systems, etc., can be integrated in this form. You only need to configure a sufficient number of compute clusters in the control center.
In terms of on-board applications, by adopting reliability enhancement techniques such as space redundancy, the N-type M-type secure computing architecture will promote the integration of on-board computing with mobile computing. Since mobile computing processors have the advantage of economies of scale, vehicle-mounted systems can not only be gradually reduced in cost, but also can keep up with the development of electronic technologies in terms of calculation speed. By displacing more sensors and vehicle-to-ground wireless communication systems, on-board control systems will be able to provide more intelligent control services for high-speed trains. For example, future on-board systems will be able to access acceleration sensors, GIS sensors, attitude sensors, radar sensors, and high-speed wireless communication systems to more smoothly control higher-speed trains.
7 Summary and Prospects
This paper presents a new type of N-based M-type security computing system based on intelligent degradation technology. Compared with the traditional security system, the system has the characteristics of high reliability, high security, low cost, high maintainability, universality, etc. The development, testing and verification of the train control system based on the system can be greatly improved. The simplification.
With the development of communication technologies and mobile computing technologies, processors will continue to maintain a significant increase in performance and a significant price drop. Under such technological trends, the choice of N-M architecture as the basic framework of the security system has avoided the traditional The fault-safety system development bottleneck problem has enabled the entire system to have good performance scalability and unparalleled economies of scale.
At the completion of this article, the State Administration of Railways has just revised and issued the Detailed Rules for the Examination and Approval of the Production of Railway Communication Signal Equipment Manufacturers, and the revised list of railway communication signal equipment has been reduced from 52 to 26, representing a reduction of 50%. The trend of future integration of train control systems has begun. It is believed that more and more train control applications will be migrated to the unified high-reliability line control platform in the future, and the train control system equipment manufacturers will also gradually transition to the line control service providers to provide users with more reliable and safer. , more customized rail transit intelligent control services.
Panoramic Lift,Safety Elevator,Observation Elevator,Safety Panoramic Elevator
XI'AN TYPICAL ELEVATOR CO., LTD , https://www.chinaxiantypical.com