Introduction to this article
On the history and current analysis of the Linux memory management reverse mapping technology, the title of the article, "The Evolution of Reverse Mapping", was later changed to "The Past and Present of Linux Memory Reverse Mapping Technology" after Xiaobian and Guo Daxia.
About the Author
Guo Jian, an ordinary kernel engineer, is interested in delving into the Linux kernel code. He is passionate about technology sharing. He hopes to bring together people with the same ideas and explore technology with a snail mentality.
(Little edited voiceover: Guo Daxia is my most admired heroes, he is a low-key, skilled and illusory, really a model of my generation of Linuxer . The big man is the country for the people.)
I. IntroductionThe mathematician Chen Shengshi said in one sentence: Understanding the changes in history is a step in understanding this subject. Today, I applied this sentence to a specific Linux module: The best way to understand reverse mapping is to understand its history. This paper introduces how the reverse mapping mechanism in the Linux kernel can be used from scratch, how to go from cumbersome to light historical process, through these historical evolution processes, I hope to have a deeper understanding of reverse mapping.
Second, the basicsBefore cutting into the history of reverse mapping, we will simply look at some basic concepts, which mainly include two aspects: one is the definition of reverse mapping, and the other is the reason for introducing reverse mapping.
1. What is reverse mapping?
Before we talk about reverse mapping, let's talk about forward mapping. When you understand forward mapping, the concept of reverse mapping is easy. The so-called forward mapping is the process of establishing a complete page table for address mapping in the case where a virtual address and a physical address (or page number, page struct) are known. For example, after a process allocates a VMA, there is no corresponding page frame (that is, no physical address is allocated). After the program accesses the VMA, an exception is generated. The kernel allocates physical pages and establishes all levels. Translation table. Through forward mapping, we can map virtual pages in the process virtual address space to corresponding page frames.
Reverse mapping, in contrast, in the case of a known page frame (probably a PFN, possibly a pointer to a page descriptor, or a physical address, the kernel has various macro definitions for converting between them), find the mapping to The virtual pages of the physical page. Since a page frame can be shared among multiple processes, the task of reverse mapping is to find all the page table entries scattered in the address space of each process.
Generally speaking, two virtual addresses are not mapped to a page frame in the address space of a process. If there are multiple mappings, then most of the pages are shared by multiple processes. The simplest example is the process fork using COW. The kernel does not allocate a new page frame until the process does not write, so the parent and child processes share a physical page. There is another example related to c lib. Since c lib is the base library, it will be file mapped to many process address spaces. Then the page frame corresponding to the program body segment in c lib should have a lot of page table entries and correspond.
2. Why do you need reverse mapping?
The reason for establishing a reverse mapping mechanism is mainly to facilitate page recycling. After the page reclaim mechanism is started, if the reclaimed page frame is located in various memory caches in the kernel (for example, slab memory allocator), then these pages can be directly recycled without related page table operations. If the page frame of the user process space is reclaimed, the kernel needs to unmapping the page frame before reclaiming, that is, find all the page table entries, and then perform corresponding modification operations. Of course, if the page is dirty, we also need some necessary disk IO operations.
A practical example can be given, such as the swapping mechanism. When an anonymous mapping page is released, all relevant page table entries are required to be changed, and the swap area and page slot index are written into the page table entry. The page can be swapped to disk only after all page table entries pointing to the page frame have been modified, and the page frame is recycled. The demand paging scenario is similar, except that all page table entries need to be cleared, so I won't go into details here.
Third, prehistoric civilizationBefore Pangu opened the earth, the universe was chaotic. For the case of reverse mapping, our question is: What is the kernel world of chaos before there is reverse mapping? This chapter is mainly to answer this question, the basis of the analysis is the source code of the 2.4.18 kernel.
1. There is no reverse mapping. How does the system work?
Perhaps young kernel engineers can hardly imagine a kernel world without reverse mapping, but in fact the 2.4 kernel is like this. Let us imagine that we are the maintainers of the page reclaim mechanism, look at our current dilemma: if there is no reverse mapping mechanism, then the struct page does not maintain any reverse mapping data. In this case, it is impossible for the kernel to find the PTEs corresponding to the page frame in a simple way. What should we do when we recycle a page frame that is shared by multiple processes?
It is not complicated to reclaim the physical page frame of the user process itself, which requires the support of the memory mapping and the swapping mechanism. These two mechanisms work similarly, except for one for the file mapped page and one for the anonymous page. However, for page recycling, they work similarly: the page frames that are infrequently used by some processes are swapped to disk, and the relationship between the process and the page frame is released. After completing these two steps, the physical page frame is completed. It is free and can be recycled to the partner system.
OK, understand the basic principles, now you need to see how to achieve: the infrequently used page frame is very easy to find (inactive lru linked list), but it is difficult to break the relationship between the page frame and the process, because there is no reverse mapping. But this is hard to beat the Linux kernel developers, they chose the method of scanning the address space of each process of the entire system.
2. How to scan the process address space?
The following figure is a schematic diagram of scanning the process address space:
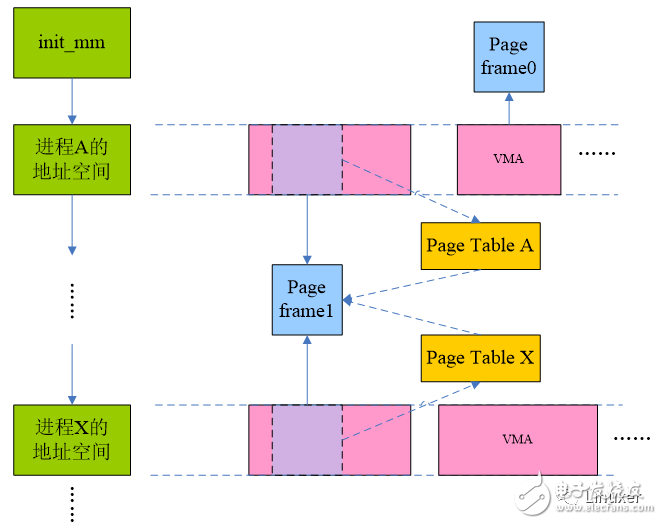
All the process descriptors in the system are serialized into a linked list, and the list header is init_mm. All the process address spaces in the system are hung in the linked list. The so-called scan is of course carried out along this mm linked list. Of course, the page recycling algorithm tries not to scan the entire process address space of the entire system. After all, it is a relatively stupid way. The recycling algorithm can consider shrinking the memory cache, or it can traverse the inactive_list to try to complete the number of reclaims (some pages in the list are not related to any process). If you release enough page frames through these methods, then everything will be fixed. There is no need for the scan process address space. Of course, the situation is not always so good. Sometimes, the process physical page recycling process must be started to meet the page recycling requirements.
The process physical page reclaim process is done by calling the swap_out function, and the code of the scan process address space begins with this function. This function is a three-level nested structure:
(1) First scan each process address space along init_mm
(2) Scanning each VMA belonging to the process address space while scanning a process address space
(3) Scan each page belonging to the VMA while scanning each VMA
During the scanning process, if the page frame 0 of process A is hit, since the page is only used by process A (ie, it is only mapped by the A process), the page can be unmapped and reclaimed directly. For the shared page, we can't handle this. For example, in the above picture frame 1 , but when the scan A process, if the conditions are met, then we will unmap the page, remove its relationship with process A, of course, this time can not Recycle the page because process X is still using the page. Until the scan process goes through the thousands of miles to the process X, the unmaping operation of the page frame 1 is completed, and the physical page can truly embrace the partner system.
3, the address space scanning details
First of all, the first question: In the end, how many virtual address spaces are scanned to stop scanning? When the target has been reached, for example, this scan intends to reclaim 32 page frames. If the target is reached, then the scan stops, and there is no need to scan all the virtual address space. There is also a more tragic situation, that is, after scanning all the address space in the system, still have not achieved the goal, this time can be stopped, but this is OOM processing. In order to ensure that the process in the system is evenly scanned (after all, swap out will affect the performance of the process, we certainly can not only catch part of the process è–… its wool), after each scan is completed, record the current scan position (stored in the swap_mm variable), Wait for the scan process to start from the swap_mm next time.
Due to the impact on performance, the swap out needs to be exposed to rain and dew, and each process can't run. By the same token, for the address space of a process, we also need to treat it fairly, so we need to save the virtual address of each scan (mm->swap_address), so that every time you restart scan, always from the address space of swap_mm The mm->swap_address virtual address starts scanning.
The code for the swap out of a page frame is located in the try_to_swap_out function. In this function, if the condition is met, the relationship between the process of the page frame is released, and the necessary IO operation is completed, and the page reference count is decremented by one. The corresponding pte is cleared or the swap entry is set. Of course, after swap out a page, we are not necessarily able to recycle it, because this page is likely to be shared by multiple processes. In the scan process, if it happens to find all the page table entries corresponding to the page, it means that the page has not been referenced by any process, and the page frame will be evicted from the disk, thereby completing the recycling of a page.
Fourth, open up the earth
Time went back to January 2002, when VM hero Rik van Riel suffered a major setback in his life, and his painstakingly maintained code was replaced by a brand new VM subsystem. However, Rik van Riel did not sink, he was making a big move, which is the legendary reverse mapping (hereafter referred to as rmap). This chapter mainly describes the first version of rmap, the code is from Linux 2.6.0.
1, design concept
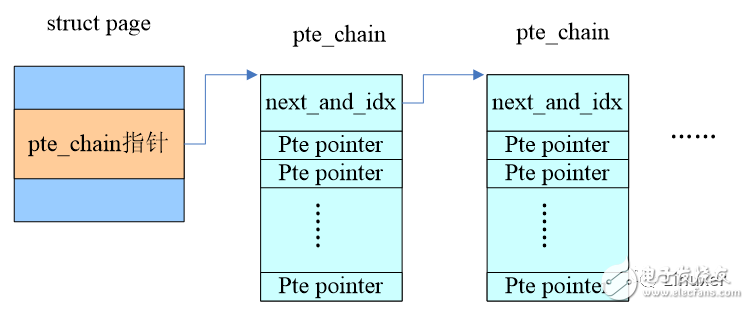
How to build rmap? The most intuitive idea is that for each page frame, we maintain a linked list that holds all the PTEs belonging to that page. Therefore, Rik van Riel adds a member of the pte chain to the struct page to string all the pte entry pointers that are mapped to the page. It's easy to unmap a page, and you can find all the mappings along this pte chain. A basic diagram is given below, and a more detailed explanation is given in the following subsections.
2 , the modification of the Struct page
The Struct page is modified as follows:
Struct page {
......
Union {
Struct pte_chain *chain;
Pte_addr_t direct;
} pte;
......
Of course, many pages are not shared, only one pte entry, so direct direct to the pte entry is OK. If there is a page sharing case, the chain member will point to a linked list of struct pte_chain.
3, define struct pte_chain
Struct pte_chain {
Unsigned long next_and_idx;
Pte_addr_t ptes[NRPTE];
} ____cacheline_aligned;
If pte_chain only saves a pointer to a pte entry, then it is too wasteful. The better way is to align the struct pte_chain in the cache line and let the entire struct pte_chain occupy a cache line. Except that next_and_idx is used to point to the next pte_chain, forming a linked list, the rest of the space is used to hold the pte entry pointer. Since the pte entry pointer forms an array, we also need an index to indicate the position of the next free pte entry pointer. Since the pte_chain is aligned in the cache line, several bits of the LSB of the next_and_idx are equal to 0, which can be reused as an index. .
4, the page recycling algorithm modification
Before we get into the rmap-based page recycling algorithm, let's recall the painful past. Suppose a physical page P is shared by two processes, A and B. In the past, the physical page of P is required to scan the process address space. First, scan to the A process to release the relationship between the P and A processes, but this time, the process cannot be recycled. The page frame is still being used. Of course, the scanning process will eventually come to the B process, and only at this time will there be a chance to recycle the physical page P. You may ask: If the scan B process address space, the A process accesses P and causes the mapping to be established. Then when scan A, the B process is accessed again, so repeatedly, then P can never be recycled? What should I do? This is theoretically like this. Don't ask me, actually I am desperate.
With rmap, the page reclaiming algorithm feels a lot easier. As long as it is the page frame of the page reclaiming algorithm, it can always be re-associated with all processes by try_to_unmap, so that it can be recycled to the partner system. If the page frame is not shared (page flag set PG_direct flag), then page->pte.direct directly hits the pte entry and calls try_to_unmap_one to perform the unmap operation. If mapped to multiple virtual address spaces, then call try_to_unmap_one along pte_chain to perform unmap operations.
Five, the son-in-law
Although Rik van Riel opened up a new world of reverse mapping, there are huge holes in heaven and earth that need someone to mend. Let us first look at this "great hole"?
After the introduction of the first version of rmap, Linux page recycling has become simple and controllable, but this simple design comes at a price: each struct page adds a pointer member, which is added on a 32-bit system. 4B. Considering that the system will create a struct page object for each page frame in order to manage memory, the memory overhead caused by introducing rmap is not a small amount. In addition, the share page needs to establish a pte_chain linked list, which is also a small memory overhead. In addition to memory pressure, the first version of rmap has a certain impact on performance. For example, in the fork operation, the parent and child processes share a lot of page frames, so that when copying the page table, it will be accompanied by a large number of pte_chain operations, which makes the speed of the fork slow.
This chapter is to take a look at how object-based reverse mapping (hereinafter referred to as objrmap) fills the "huge hole". The code for this chapter comes from the kernel version 2.6.11.
1. Introduction of the problem
The driving force behind rmap optimization comes from the memory pressure. The related question is whether the 32-bit Linux kernel supports more than 4G memory. In 1999, Linus decided that the 32-bit Linux kernel would never support more than 2G of memory. But the history of the flood is unstoppable, processor manufacturers have designed expansion modules to address more memory, and high-end servers are also configured with more and more memory. This also forced Linus to change the previous thinking and let the Linux kernel support more memory.
What Red Hat's Andrea Arcangeli was doing at the time was to have 32-bit Linux running on a corporate server with more than 32 GB of memory. A large number of processes are often started on these servers, sharing a large number of physical page frames and consuming a large amount of memory. For Andrea Arcangeli, the real culprit in memory consumption is clear: the reverse mapping module, which consumes too much low memory, causing various crashes in the system. In order for his work to continue, he must solve the memory scalability problem introduced by rmap.
2, file mapped optimization
Not only Andrea Arcangeli is concerned about the memory problem of rmap. In the development of version 2.5, IBM's Dave McCracken has submitted a patch, trying to correct the reverse mapping function and at the same time correcting the various effects brought by rmap. problem.
Dave McCracken's solution is an object-based reverse mapping mechanism. In the past, through rmap, we can directly obtain the corresponding ptes from the struct page. The objrmap method uses other data objects to complete the process of retrieving from the struct page to its corresponding ptes. The schematic diagram of this process is as follows:
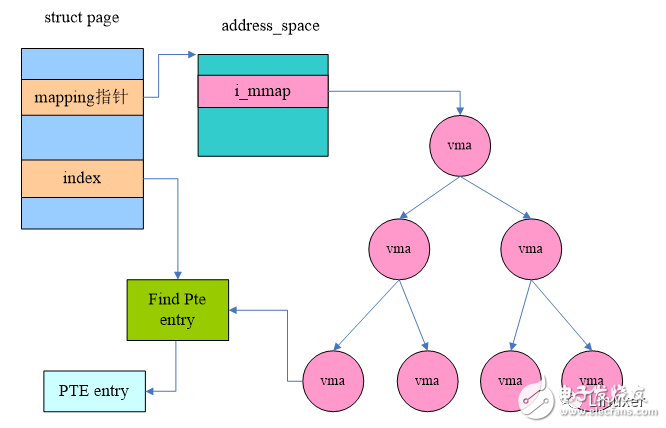
For objrmap, looking for a page frame's mappings is a relatively long path, which uses the VMA (struct vm_area_struct) data object. We know that for some page frames there are backup files. This type of page is related to a file, such as the body of the process and the executable file of the process. In addition, the process can call mmap() to map a file. For these page frames we call the file mapped page.
For these file mapping pages, a member mapping in the struct page points to a struct address_space, which is associated with the file, which holds information about the file page cache. Of course, our scenario focuses on a member called i_mmap. A file may be mapped to multiple VMAs of multiple processes, all of which are linked to the Priority search tree pointed to by i_mmap.
Of course, our ultimate goal is PTEs. The following figure shows how to derive the virtual address of the page frame from the information in the VMA and struct pages:
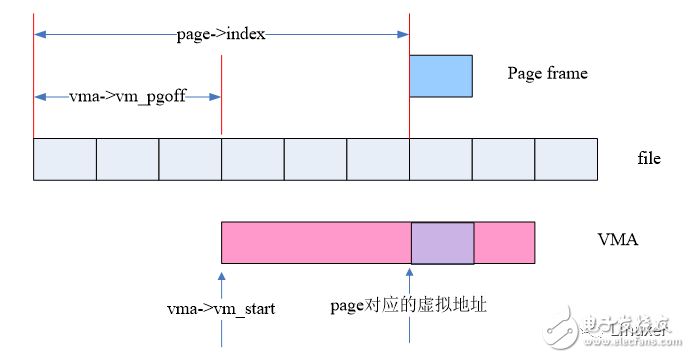
In the Linux kernel, the function vma_address can do this:
Static inline unsigned long
Vma_address(struct page *page, struct vm_area_struct *vma)
{
Pgoff_t pgoff = page->index << (PAGE_CACHE_SHIFT - PAGE_SHIFT);
Unsigned long address;
Address = vma->vm_start + ((pgoff - vma->vm_pgoff) << PAGE_SHIFT);
Return address;
}
For the file mapped page, page->index indicates the offset (in Bytes) mapped to the file, and vma->vm_pgoff indicates the offset (page unit) of the VMA mapped into the file. Therefore, The address offset of the page frame in the VMA can be obtained by vma->vm_pgoff and page->index, and the virtual address of the page frame can be obtained by adding vma->vm_start. With the virtual address and address space (vma->vm_mm), we can find the pte entry corresponding to the page through the various levels of the page table.
3, the optimization of anonymous pages
We all know that there are two main types of pages in the user space process, one is the file mapped page, and the other is the anonymous mapped page. Dave McCracken's objrmap solution is good, but it only works on file mapped pages. For anonymous mapping pages, this solution can't do anything. Therefore, we must also design an object-based reverse mapping mechanism for anonymous mapping pages, and finally form a full objrmap scheme.
To solve the problem of memory scalability, Andrea Arcangeli worked on the full objrmap solution, but he also had a competitor, Hugh Dickins, and also submitted a series of full objrmap patches, trying to merge into the kernel mainline, apparently in anonymous mapping. On the page, the final winner is Andrea Arcangeli, whose anonymous mapping scheme is shown below:
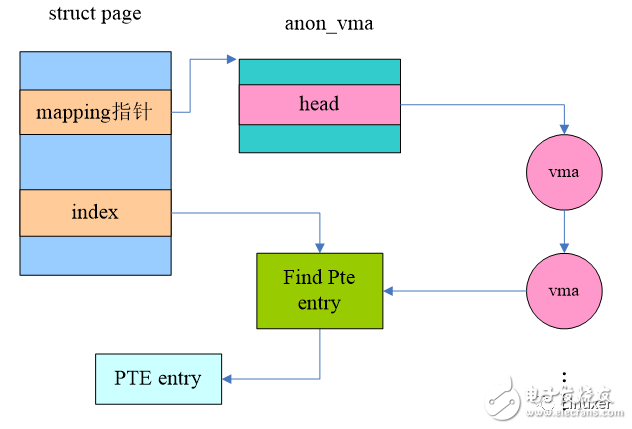
Similar to file mapping, anonymous page is also used to find the pte entry corresponding to the page frame through VMA. Since the number of VMAs on the file map page can be very large, we use a data structure such as the Priority search tree. For anonymous mapping pages, the number is generally not too large, so using the linked list structure is OK.
In order to save memory, we reuse the mapping pointer in the struct page: if a page frame is file mapped, its mapping pointer points to the address_space data structure of the corresponding file. If it is an anonymous page, then the mapping pointer points to the anon_vma data structure. Although the memory is saved, but the readability is reduced, but since the kernel will create a corresponding struct page data object for each page frame, even if the data structure is increased by 4B, the memory consumption of the entire system is huge, so the kernel Still adopt a more ugly way to define the mapping member. Through the mapping member in the struct page we can get the information related to the page mapping, summarized as follows:
(1) is equal to NULL, indicating that the page frame is no longer in memory, but is swapped out to disk.
(2) If it is not equal to NULL, and the least signification bit is equal to 1, it indicates that the page frame is an anonymous mapping page, and the mapping points to an anon_vma data structure.
(3) If it is not equal to NULL, and the least signification bit is equal to 0, it means that the page frame is a file mapping page, and the mapping points to the address_space data structure of the file.
Through the anon_vma data structure, we can get all the VMAs mapped to the page. At this point, the anonymous mapping and file mapped confluence, the further solution is only how to get from VMA to pte entry. In the previous section, we described how the vma_address function gets the virtual address of the file mapped page. In fact, the logic of the anonymous page is the same, except that the base points of vma->vm_pgoff and page->index are different, for the file mapped scene. The basic point is the starting position of the file. For anonymous mapping, there are two cases for the starting point. One is share anonymous mapping, and the starting position is 0. The other is private anonymous mapping, where the starting point is the virtual address of the mapping (divided by page size). But no matter what, the algorithm concept of getting the corresponding virtual address from VMA and struct page is similar.
Sixth, come back
After full objrmap enters the kernel, it seems that everything is perfect. Compared to her predecessor, Rik van Riel's rmap solution, objrmap all aspects of the indicators are fully rolled rmap. Rik van Riel, the great god who introduced the reverse mapping to the kernel for the first time, suffered a second blow, but he still struggled and tried to make a comeback.
Objrmap is perfect, but there is a dark cloud in the clear sky. The great god Rik van Riel was keenly aware of the "black cloud" of the reverse mapping and proposed his own solution. This chapter mainly describes the new anon_vma mechanism, the code comes from the 4.4.6 kernel.
1. What is wrong with the old anon_vma mechanism?
Let's take a look at how the system works under the old anon_vma mechanism. VMA_P is an anonymously mapped VMA of the parent process. Both A and C have been assigned page frames, and no other pages have assigned physical pages. After fork, the child process copies VMA_P. Of course, due to the adoption of COW technology, the anonymous pages of the parent and child processes will be shared at this time, and the write protect flag is marked in the pte entry corresponding to the address space of the parent and child processes, as shown in the following figure:
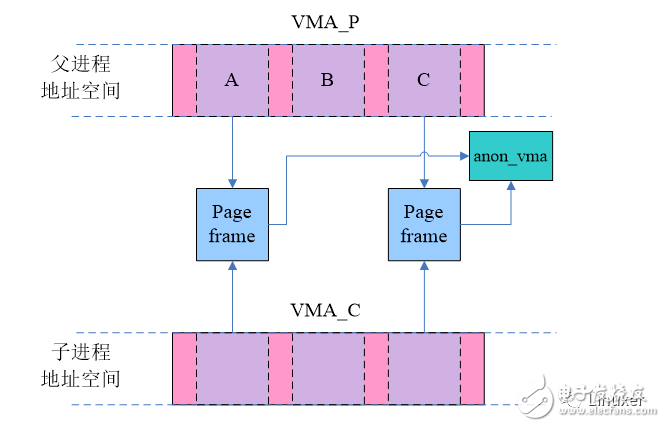
It is reasonable to say that anonymous pages of different processes (such as stack, heap) are private and will not be shared, but in order to save memory, after the parent process fork child process, the parent and child processes are written to the page before the anonymous page of the parent and child processes is Shared, so these page frames point to the same anon_vma. Of course, the sharing is only short-lived. Once there is a write operation, an exception is generated, and the page frame is allocated in the exception handling, and the sharing of the anonymous pages of the parent-child process is cancelled, as shown in the following page A:
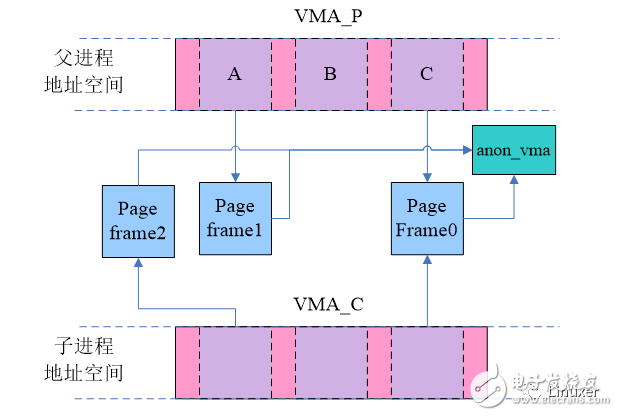
At this time, due to the write operation, the page frames shared by the parent and child processes are no longer shared. However, the two pages still point to the same anon_vma. Not only that, but for pages like B, they are not shared between the parent and child processes at the beginning. When the first time access (whether the parent process or the child process), the page frame allocated by the do_anonymous_page function also points to an anon_vma. In other words, the VMA of the parent and child processes share an anon_vma.
In this case, let's see what happens to unmap page frame1. There is no doubt that the mapping member of the struct page corresponding to page frame1 points to the anon_vma in the above figure. The traversal of anon_vma will kill VMA_P and VMA_C. In this case, VMA_C is an invalid VMA, which should not be matched. If the aon_vma list is not that long, then the overall performance is OK. However, in some network servers, the system relies heavily on fork, and a service program may fork a large number of child processes to process service requests. In this case, system performance is seriously degraded. Rik van Riel gives a concrete example: there are 1000 processes in the system, all generated by fork, and each process's VMA has 1000 anonymous pages. According to the current software architecture, there are 1000 vma nodes in the anon_vma list, and one million anonymous pages in the system belong to the same anon_vma.
What kind of problems can such a system cause? Let's take a look at the try_to_unmap_anon function, whose code framework is as follows:
Static int try_to_unmap_anon(struct page *page)
{...
Anon_vma = page_lock_anon_vma(page);
List_for_each_entry(vma, &anon_vma->head, anon_vma_node) {
Ret = try_to_unmap_one(page, vma);
}
Spin_unlock(&anon_vma->lock);
Return ret;
}
When a CPU in the system executes the try_to_unmap_anon function, it needs to traverse the VMA list, and this will hold the spin lock of anon_vma->lock. Since anon_vma has a lot of VIAs that are not related at all, through the retrieval process of page table, you will find that this VMA has nothing to do with the page for unmap, so you can only scan the next VMA. The whole process takes a lot of time and is extended. The critical section (complexity is O(N)). At the same time, when other CPUs try to acquire the lock, they will basically get stuck. At this time, the performance of the entire system can be imagined. What's even worse is that not only unmap anonymous pages in the kernel are locked, traversed by the VMA list, but also in other scenarios (such as the page_referenced function). Imagine that a million pages share this anon_vma, and the competition for the anon_vma->lock spin lock is quite fierce.
2, improved program
The crux of the old solution is that anon_vma hosts a VMA with too many processes. If it can be turned into a per-process, then the problem is solved. Rik van Riel's solution is to create an anon_vma structure for each process and link the parent-child process's anon_vma (hereafter referred to as AV) and VMA through various data structures. In order to link anon_vma, the kernel introduces a new structure called anon_vma_chain (hereafter referred to as AVC):
Struct anon_vma_chain {
Struct vm_area_struct *vma; - points to the VCA corresponding to the AVC
Struct anon_vma *anon_vma; - point to the AV corresponding to the AVC
Struct list_head same_vma; -- link to the node of the VMA list
Struct rb_node rb; --- link to the node of the AV red black tree
Unsigned long rb_subtree_last;
};
AVC is a magical structure, and each AVC has its corresponding VMA and AV. All AVCs pointing to the same VMA will be linked into a linked list, which is the anon_vma_chain member of the VMA. An AV will manage several VMAs. All related VMAs (its child processes or grandchildren) are hooked into the red-black tree, and the root node is the rb_root member of the AV.
This description is very boring. It is estimated that the students who are exposed to the reverse mapping for the first time will not understand. Let's take a look at how the "buildings" of AV, AVC and VMA are built.
3. When VMA and VA meet for the first time
Due to the adoption of COW technology, anonymous pages of child processes and parent processes are often shared until one of them initiates a write operation. But if the child process executes the system call of exec and loads its own binary image, then the execution environment of the child process and the parent process (including the anonymous page) will be divided (refer to the flush_old_exec function), our scene is from such a The process after the new exec starts. When the anonymous mapping VMA of the process allocates the first page frame through the page fault, the kernel constructs the data relationship shown in the following figure:
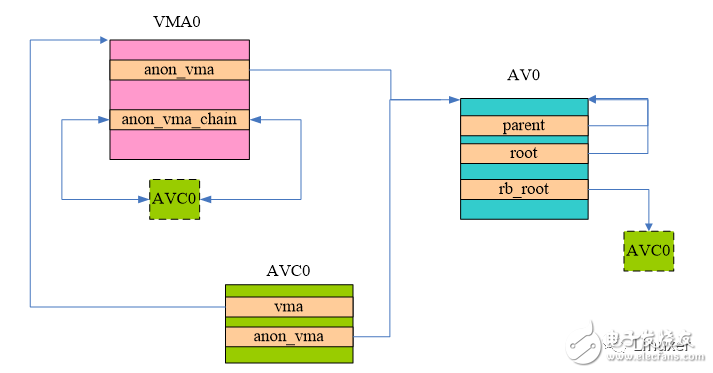
The AV0 in the above figure is the aon_vma of the process. Since it is a top-level structure, its root and parent point to itself. The AV data structure is of course to manage the VMA, but in the new mechanism, this is relayed through AVC. The AVC0 in the above figure builds a bridge between the VMA and the AV. The pointers point to VMA0 and AV0 respectively. In addition, AVC0 is inserted into the red and black trees of the AV, and is also inserted into the linked list of the VMA.
For this newly allocated page frame, it will be mapped to a virtual address corresponding to the VMA. In order to maintain the reverse mapping relationship, the mapping in the struct page points to AV0, and the index member points to the page in the entire VMA0. Offset. This relationship is not shown in the picture, mainly because it is a commonplace, I believe everyone is already familiar with it.
VMA0 may then have several page frames mapped to a virtual page of the VMA, but the above structure does not change, except that the mapping in each page points to AV0 in the above figure. In addition, the AVC0 of the dotted green block in the above figure is actually equal to the AVC0 block of the green solid line. That is to say, at this time, the VMA has only one anon_vma_chain, that is, AVC0. The above figure is only convenient to indicate that the AVC will also be linked to the linked list of the VMA. , hang into the red black tree of anon_vma.
If you want to refer to the relevant code, you can take a closer look at do_anonymous_page or do_cow_fault.
4. At the time of fork, what did the anonymously mapped VMA experience?
Once fork, the child process will copy the parent process's VMA (reference function dup_mmap), the child process will have its own VMA, and will also allocate its own AV (the old mechanism, multiple processes share an AV, and the new mechanism In the middle, AV is per process), and then establish the "building" of the VMA and VA between the parent and child processes. The main steps are as follows:
(1) call the anon_vma_clone function to establish the relationship between the child process VMA and the "parent process" VA
(2) Establish the relationship between the child process VMA and the child process VA
How to establish the relationship between VMA and VA? In fact, it is the calling process of the anon_vma_chain_link function, the steps are as follows:
(1) Assign an AVC structure, the member pointer points to the corresponding VMA and VA
(2) Add the AVC to the VMA linked list
(3) Add the AVC to the VA Red Black Tree
Let's start by not making things too complicated. Let's take a look at the scene of a new process fork subprocess. At this time, the kernel will construct the data relationship shown in the following figure:
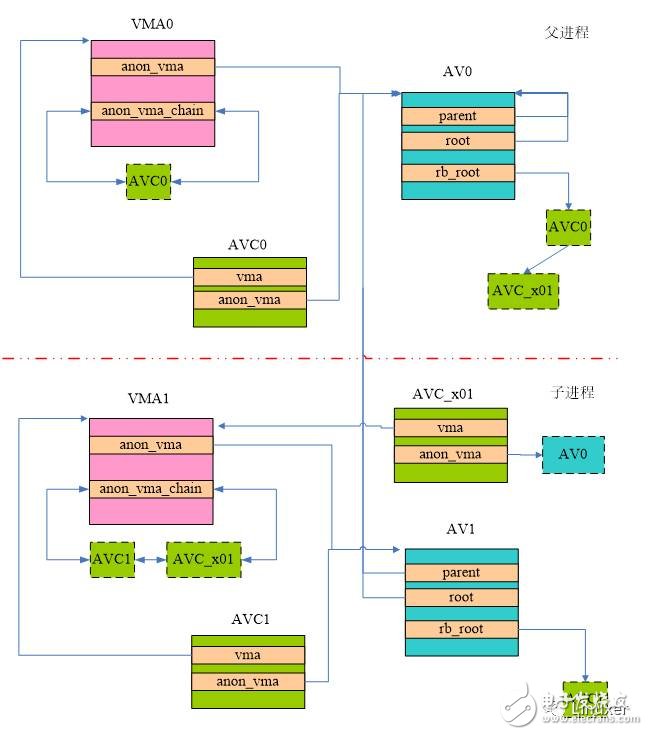
First look at how to establish the relationship between the child process VMA1 and the parent process AV0, here you need to traverse the VMA0 anon_vma_chain linked list, of course, this list has only one AVC0 (link to AV0), in order to establish contact with the parent process, we assigned AVC_x01, it It is a bridge that connects the father and child processes. (Note: x in AVC_x01 indicates connection, 01 indicates connection level 0 and level 1). Through this bridge, the parent process can find the VMA of the child process (because AVC_x01 is inserted into the red black tree of AV0), and the child process can also find the AV of the parent process (because AVC_x01 is inserted into the linked list of VMA1).
Of course, your own anon_vma also needs to be created. In the above figure, AV1 is the aon_vma of the child process, and an AVC1 is allocated to connect the VMA1 and AV1 of the child process, and the acon_vma_chain_link function is called to insert AVC1 into the linked list of VMA1 and the red-black tree of AV1.
The parent process will also create other new child processes. The level of the newly created child process is similar to that of VMA1 and VA1, which is not described here. However, it should be noted that each time a parent process creates a child process, the AVC of the AV0 will add each AVC that acts as a "bridge" to connect to the VMA of the child process.
5, build a three-story building
The previous section described the parent process to create a child process. If the child process forks again, the entire VMA-VA building will form a three-tier structure, as shown in the following figure:
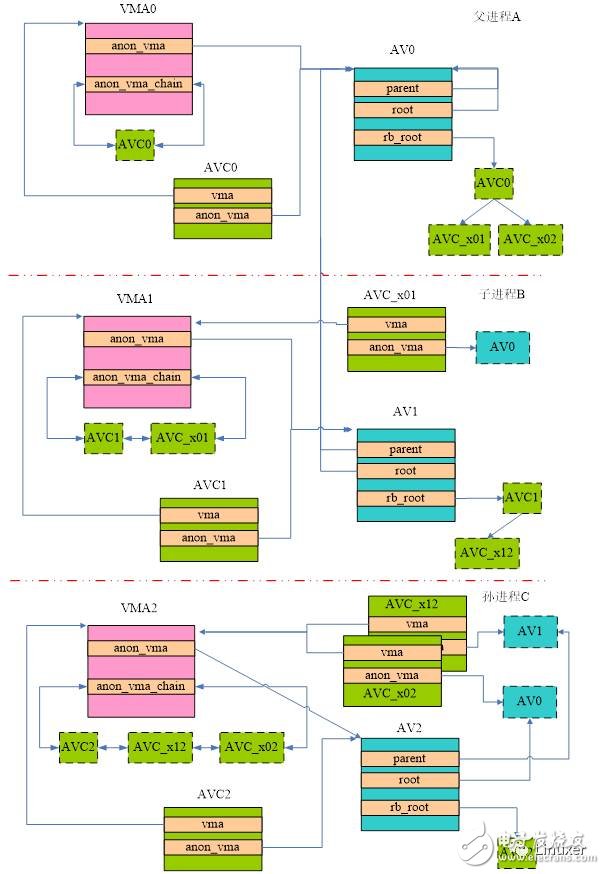
Of course, the first thing to do is to establish the relationship between the grandchild process VMA and the "parent process" VA. The "parent processes" here are actually those processes that refer to the upper level of the grandchild process. For this scenario, the "parent processes" refer to the A process and the B process in the above figure. How to build? At fork, we make a copy of the VMA: allocate VMA2 and copy it to VMA2 with VMA1 as the prototype. Copy is performed along the AVC linked list of VMA1, which has two elements: AVC1 and AVC_x01, which are associated with the AV of parent process A and child process B, respectively. Therefore, in Sun Process C, we will assign two AVCs of AVC_x02 and AVC_x12, and establish the relationship between level 2 and level 0 and level 1.
Similarly, the own level of anon_vma also needs to be created. In the above figure, AV2 is the anon_vma of the grandchild C, and assigns an AVC2 to connect the VMA2 and AV2 of the grandchild process, and calls the anon_vma_chain_link function to insert AVC2 into the linked list of VMA2 and the red black tree of AV2.
The root in AV2 points to root AV, which is the AV of process A. The Parent member points to the AV of its B process (the parent of C). With pointers such as Parent, AVs of different levels establish a parent-child relationship, and each level of AV can find a root AV through the root pointer.
6. How does the page frame join the “building�
The previous sections focus on how the structure of the hierarchy AV is built, that is, how the VMA, AVC, and AV of the parent and child processes are related in the process of describing the fork. In this section we will take a look at one of the parent and child processes to access the page, the page fault process has occurred. There are two scenarios in this process. One is that the parent and child processes do not have a page frame. At this time, the kernel code will call do_anonymous_page to allocate the page frame and call the page_add_new_anon_rmap function to establish the relationship between the page and the corresponding VMA. The second scene is more complicated. It is the scene where the father and the son share the anonymous page. When a write fault occurs, the page frame is also allocated and the page_add_new_anon_rmap function is called to establish the relationship between the page and the corresponding VMA. The specific code is located in the do_wp_page function.æ— è®ºå“ªä¸€ä¸ªåœºæ™¯ï¼Œæœ€ç»ˆéƒ½æ˜¯å°†è¯¥pageçš„mappingæˆå‘˜æŒ‡å‘了该进程所属的AV结构。
7ã€ä¸ºä½•å»ºç«‹å¦‚æ¤å¤æ‚的“大厦â€ï¼Ÿ
å¦‚æžœä½ èƒ½åšæŒè¯»åˆ°è¿™é‡Œï¼Œé‚£ä¹ˆè¯´æ˜Žä½ 对枯燥文å—çš„å¿å—能力还是很强的,哈哈。Pageã€VMAã€VACã€VA组æˆäº†å¦‚æ¤å¤æ‚çš„å±‚æ¬¡ç»“æž„åˆ°åº•æ˜¯ä¸ºä»€ä¹ˆå‘¢ï¼Ÿæ˜¯ä¸ºäº†æ‰“å‡»ä½ å¦ä¹ å†…æ ¸çš„å…´è¶£å—?éžä¹Ÿï¼Œè®©æˆ‘们还是用一个实际的场景æ¥è¯´æ˜Žè¿™ä¸ªâ€œå¤§åŽ¦â€çš„功能。
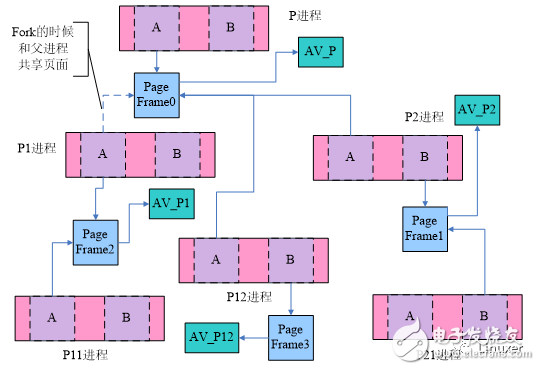
我们通过下é¢çš„æ¥éª¤å»ºç«‹èµ·ä¸Šå›¾çš„结构:
(1)P进程的æŸä¸ªVMAä¸æœ‰ä¸¤ç±»é¡µé¢ï¼š 一类是有真实的物ç†é¡µé¢çš„,å¦å¤–一类是还没有é…备物ç†é¡µé¢çš„。上图ä¸ï¼Œæˆ‘们分别跟踪有物ç†é¡µé¢çš„A以åŠè¿˜æ²¡æœ‰åˆ†é…物ç†é¡µé¢çš„B。
(2)P进程fork了P1和P2
(3)P1进程fork了P12进程
(4)P1进程访问了A页é¢ï¼Œåˆ†é…了page frame2
(5)P12进程访问了B页é¢ï¼Œåˆ†é…了page frame3
(6)P2进程访问了B页é¢ï¼Œåˆ†é…了page frame1
(7)P2进程fork了P21进程
ç»è¿‡ä¸Šé¢çš„这一些动作之åŽï¼Œæˆ‘们æ¥çœ‹çœ‹page frame共享的情况:对于P进程的page frame(是指该page çš„mappingæˆå‘˜æŒ‡å‘P进程的AV,å³ä¸Šå›¾ä¸çš„AV_P)而言,他å¯èƒ½ä¼šè¢«ä»»ä½•ä¸€ä¸ªlevelçš„çš„å进程VMAä¸çš„pageæ‰€æœ‰å…±äº«ï¼Œå› æ¤AV_P需è¦åŒ…括其å进程ã€å™è¿›ç¨‹â€¦â€¦çš„所有的VMA。而对于P1进程而言,AV_P1则需è¦åŒ…括P1å进程ã€å™è¿›ç¨‹â€¦â€¦çš„所有的VMA,有一点å¯ä»¥ç¡®è®¤ï¼šè‡³å°‘父进程P和兄弟进程P2çš„VMAä¸éœ€è¦åŒ…括在其ä¸ã€‚
现在我们回头看看AV结构的大厦,实际上是符åˆä¸Šé¢çš„需求的。
8ã€é¡µé¢å›žæ”¶çš„时候,如何unmap一个page frameçš„æ‰€æœ‰çš„æ˜ å°„ï¼Ÿ
æ建了那么å¤æ‚çš„æ•°æ®ç»“构大厦就是为了应用,我们一起看看页é¢å›žæ”¶çš„场景。这个场景需è¦é€šè¿‡page frameæ‰¾åˆ°æ‰€æœ‰æ˜ å°„åˆ°è¯¥ç‰©ç†é¡µé¢çš„VMAs。有了å‰é¢çš„铺垫,这并ä¸å¤æ‚,通过struct pageä¸çš„mappingæˆå‘˜å¯ä»¥æ‰¾åˆ°è¯¥page对应的AV,在该AVçš„çº¢é»‘æ ‘ä¸ï¼ŒåŒ…å«äº†æ‰€æœ‰çš„å¯èƒ½å…±äº«åŒ¿å页é¢çš„VMAs。éåŽ†è¯¥çº¢é»‘æ ‘ï¼Œå¯¹æ¯ä¸€ä¸ªVMA调用try_to_unmap_one函数就å¯ä»¥è§£é™¤è¯¥ç‰©ç†é¡µå¸§çš„æ‰€æœ‰æ˜ å°„ã€‚
OK,我们å†æ¬¡å›žåˆ°è¿™ä¸€ç« 的开始,看看那个长临界区导致的性能问题。å‡è®¾æˆ‘们的æœåŠ¡å™¨ä¸Šæœ‰ä¸€ä¸ªæœåŠ¡è¿›ç¨‹A,它fork了999个å进程æ¥ä¸ºä¸–ç•Œå„地的网å‹æœåŠ¡ï¼Œè¿›ç¨‹A有一个VMA,有1000个page。下é¢æˆ‘们就一起æ¥å¯¹æ¯”新旧机制的处ç†è¿‡ç¨‹ã€‚
首先,百万page共享一个anon_vma的情况在新机制ä¸å·²ç»è§£å†³ï¼Œæ¯ä¸€ä¸ªè¿›ç¨‹éƒ½æœ‰è‡ªå·±ç‰¹æœ‰çš„anon_vma对象,æ¯ä¸€ä¸ªè¿›ç¨‹çš„page都指å‘自己特有的anon_vma对象。在旧的机制ä¸ï¼Œæ¯æ¬¡unmap一个page都需è¦æ‰«æ1000个VMA,而在新的机制ä¸ï¼Œåªæœ‰é¡¶å±‚的父进程Açš„AVä¸æœ‰1000个VMA,其他的å进程的VMA的数目都åªæœ‰1个,这大大é™ä½Žäº†ä¸´ç•ŒåŒºçš„长度。
七ã€åŽè®°
本文带领大家一起简略的了解了逆å‘æ˜ å°„çš„å‘展过程。当然,时间的车轮永ä¸åœæ¯ï¼Œé€†å‘æ˜ å°„æœºåˆ¶è¿˜åœ¨ä¸æ–çš„ä¿®æ£ï¼Œå¦‚æžœä½ æ„¿æ„,也å¯ä»¥äº†è§£å…¶æ¼”进过程的基础上,æ出自己的优化方案,在其历å²ä¸Šç•™ä¸‹è‡ªå·±çš„å°è®°ã€‚
Digital Load Cell is our new arrival load cells , digital output RS232 or RS485 , It made of aluminum alloy material, have 5kg, 10kg, 30kg , 40kg capacity and we recommend the max platform of it is 250×350mm.C4 high accuracy load cell, used for electronic counting scales, smart shelves, etc which needs high quality weighing condition.
Digital Load Cell,Electronic Load Cell,Load Cell With Digital Readout,Digital Load Cell Weight Sensor,load cell 5kg
GALOCE (XI'AN) M&C TECHNOLOGY CO., LTD. , https://www.galoce-meas.com