introduction
This paper introduces an implementation method of a Chinese speech synthesis system based on DSP. With the continuous development and maturity of voice signal processing technology, speech synthesis is gradually becoming the key technology of human-machine interface in information technology. The DSP chip, the digital signal processor, is a microprocessor with a special structure designed to quickly implement various signal processing algorithms. The processing speed is 10 to 50 times faster than the fastest CPU.
1 system overall plan
The most important feature of speech synthesis is to synthesize continuous sentences of infinite vocabulary from a limited number of storage units [1]. In order to do this, the system is designed by (1) the front-end preprocessing module converts the input text file into a standard format that the system can handle; (2) the prosody rule library gives the prosodic feature parameters of each syllable in the current locale; (3) The speech synthesizer adjusts the acoustic parameters of the corresponding speech units in the original speech library according to the given prosodic feature parameters; (4) splicing the adjusted speech units together to obtain a continuous speech output corresponding to the input text. Wait for 4 basic processes. The basic principle block diagram of the system is shown in Figure 1.
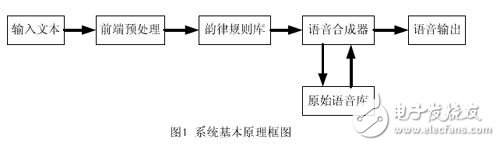
2 hardware system design
The purpose of the Chinese speech synthesis system is to output the input text file in a clear, natural, and understandable manner in continuous speech. ATMEL's AT89S52 MCU displays the text file input by the keyboard, and then sends it to the TMS320VC5402 for processing. Finally, the synthesized result is output. The hardware structure block diagram is shown as in Fig. 2.

2.1 keyboard circuit and display circuit
The keyboard interface circuit of AT89S52 adopts the interrupt mode. When a key is pressed, an interrupt request is generated, the interrupt processing is entered, and then the corresponding processing is performed by querying the cases of P1.0 and P1.1. With the resistor and capacitor enough to become a debounce circuit to prevent misoperation of the circuit.
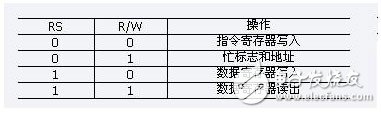
The AT89S52 sends the text information input from the keyboard to the LCD display, and writes the data to the external memory CY7C133. Then the TMS320 VC5402 reads the information on the CY7C133 for processing. The instruction format of the LCD is shown in Table 1:
Table 1 LCD instruction format
![]()
Where RS, R/W jointly decide which register to choose, as shown in Table 2:
Table 2 Register Selection
2.2 Communication between TMS320VC5402 and AT89S52
The AT89S52 and TMS320VC5402 work independently, and their information and data exchange are realized by sharing a piece of external memory. The signal communication between them is realized by hard connection and software judgment [2].
The external memory uses the CY7C133, which is a high-speed 2K X 16bit static asynchronous dual-port RAM with a storage speed of 25ns. It has two separate address lines, data lines, and control signal lines that allow data from two control devices to communicate through a commonly connected memory. The dual port RAM allows two controllers to simultaneously read any memory location (including reading the same unit simultaneously), but does not allow simultaneous writes or read and write of a uniform address location.
For the TMS320VC5402, the corresponding address of the data memory CY7C133 is 4000H~47FFH.
For the AT89S52, the corresponding address of the data memory CY7C133 is 2000H~27FFH.
3 software system design
As a kind of tuned language, Chinese has a very complex rhythm. In order to synthesize continuous sentences of infinite vocabulary from a limited storage unit, the prosody parameters of the speech library unit must be adjusted under certain prosody rules to obtain a permutation unit that conforms to the current stream environment [3].
According to the method of obtaining the sound change unit, the speech synthesizer can be divided into two types: (1) waveform stitching synthesis; (2) parameter synthesis (also called source/filter synthesis). The system uses waveform stitching synthesis method to directly adjust the time domain and frequency domain waveform of the waveform to obtain the required sound unit.
Simple waveform stitching is difficult to adjust pitch and length (time length). Therefore, the system adopts the neutral language tuning syllable directly splicing with the pitch synchronization waveform superposition (PSOLA) algorithm, and uses the code excitation linear prediction (CELP) coding method to encode and compress the original sampled sound library. The basic flow chart is shown in Figure 3.



4 Conclusion
The system uses SCM to display the input text file in real time, which can compare and output the synthesized speech and the input text file, and has strong intuitiveness; the synthesis algorithm has low computational complexity, and can realize the storage space with limited capacity by using the sound library as small as possible. The degree of occupancy requires clarity, intelligibility and high naturalness.
LED street lights achieve ultra brightness/luminance; energy-saving over 70%. Special modular design for theLens (independent modules) and high luminous efficacy, high CRI, easy for maintenance.Intelligent and isolated power supply (NS semiconductor and Japan Rubycon capacitor), reliable and stable; automatically reduce current against overheating working temperature
Single Arm Led Street Light,Solar Lighting Street,Led Street Light Module
Yangzhou Beyond Solar Energy Co.,Ltd. , https://www.ckbsolar.com