Data analyst Seth Grimes once pointed out that "80% of commercial information comes from unstructured data, mainly textual data." This statement may exaggerate the proportion of text data in business data, but the value of the information contained in text data is not worth Doubt. Matthew Mayo, editor of KDnuggets, a machine learning researcher and data scientist, wrote a series of articles about text data analysis on the website. This article is the first of the series. It mainly describes the general steps and framework of text data analysis. The following is the compilation of the original wisdom on the original text.
Although NLP and text mining are not the same thing, they are still closely related: they deal with the same raw data types, and there are many crossovers when they are used. Below we describe the processing steps of these tasks.
Today's text data volume is very large, many of them are generated from daily life, including both structured and semi-structured and even chaotic data. What can we do about it? In fact, there are many things that can be done, depending on what your goals are.
Text mining or natural language processing?
Natural language processing (NLP) focuses on the interrelationship between human natural language and computer devices. NLP is one of the important aspects of computer linguistics. It also belongs to the fields of computer science and artificial intelligence. While text mining is similar to the NLP's existence field, it focuses on identifying interesting and important patterns in text data.
However, the two are still different. First of all, these two concepts are not clearly defined (like "data mining" and "data science"), and the two are intertwined to varying degrees, depending on who you are talking to. I think it's easiest to distinguish by level of insight. If the original text is data, text mining is information, and NLP is knowledge, which is the relationship between grammar and semantics. The following pyramid shows this relationship:
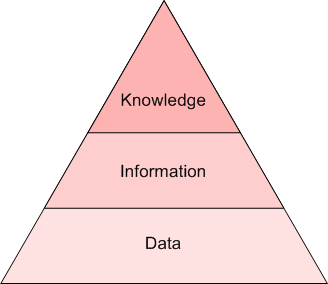
Another way to distinguish these two concepts is to distinguish them by the Wayne diagram below, which also involves other related concepts, so as to better represent the overlapping relationship between them.
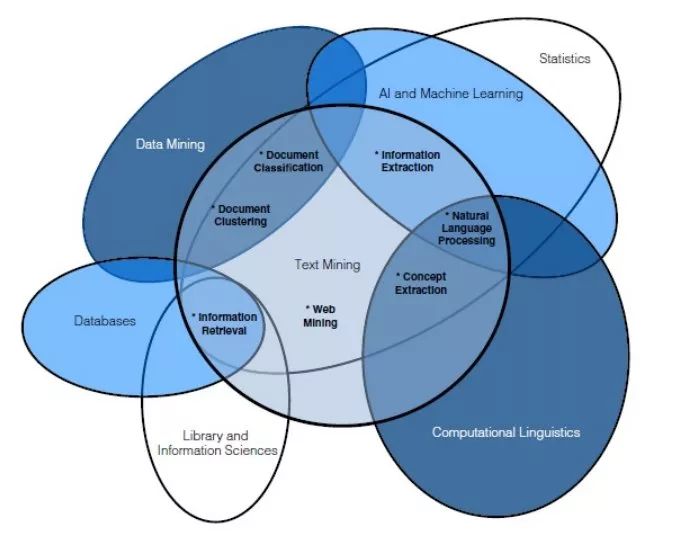
Our goal is not an absolute or relative definition of the two. It is important to realize that the preprocessing of data under these two tasks is the same.
Efforts to eliminate ambiguity are an important aspect of text preprocessing. We hope to preserve the original meaning and eliminate noise at the same time. To do this, we need to understand:
Knowledge about language
Knowledge about the world
Ways to combine knowledge sources
In addition, the following six factors also increase the difficulty of text data processing, including non-standard language expressions, segmentation problems, idioms, new vocabulary, common sense, and complex nouns.

Text Data Science Task Framework
Can we make an efficient and universal framework for the processing of text data? We found that the processing of text is very similar to the processing of other non-text tasks. See the KDD Process I wrote earlier for reference.
The following are the major steps in dealing with text tasks:
1. Data collection
Get or create corpora, sources can be emails, English Wikipedia articles or company earnings, and even Shakespeare's works and any other information.
2. Data preprocessing
Preprocessing on raw text corpora to prepare for text mining or NLP tasks
Data preprocessing is divided into several steps, some of which may or may not apply to a given task. But usually it is one of tokenization, normalization, and substitution.
3. Data Mining and Visualization
No matter what our data type, mining and visualization is an important step in the search for rules
Common tasks may include visualizing word counts and distributions, generating wordclouds, and performing distance measurements
4. Model building
This is the main part of text mining and NLP tasks, including training and testing
When appropriate, feature selection and engineering
Language Models: Vector Space Modeling of Finite State Machines, Markov Models, and Word Meanings
Machine Learning Classifiers: Naive Bayes, Logistic Regression, Decision Trees, Support Vector Machines, Neural Networks
Sequence Models: Hidden Markov Models, Recurrent Neural Networks (RNN), and Long-term and Short-term Memory Neural Networks (LSTMs)
5. Model assessment
Does the model achieve expectations?
Metrics will vary depending on the type of text mining or NLP task
Even if you don’t do a chatbot or a generative model, some form of assessment is necessary.
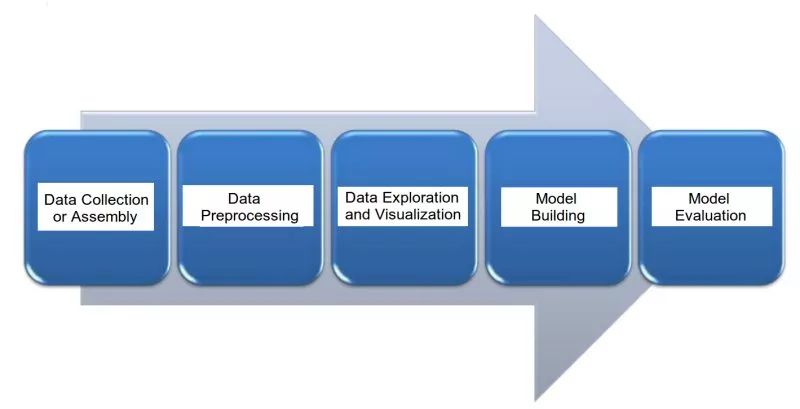
In the next serialization, I will bring you further exploration of the framework for data preprocessing in the text data task, so stay tuned.
Solar Panel Connectors,Solar Connector,Mc4 Solar Connector,Solar Panel Connectors Types
NANTONG RONGCHANG IMPORT&EXPORT CO.,LTD , https://www.ergsolarcn.com